v2.3.1 / Open Source / AGPL-3.0
Your AI. Your machine.
No limits.
Chat, code, generate images, create videos — all running locally. Plug & Play with 12 local backends. 13 built-in tools, coding agent. No cloud, no accounts.
Chat, code, generate images, create videos — all running locally. Plug & Play with 12 local backends. 13 built-in tools, coding agent. No cloud, no accounts.
Download v2.3.1
Plug & Play — choose from 20+ providers. The setup wizard auto-detects 12 local backends (Ollama, LM Studio, vLLM, KoboldCpp, Jan, GPT4All, llama.cpp, and more) or configure cloud APIs in Settings. Other platforms: build from source.
Web search, file I/O, shell commands, code execution, screenshots, system info. Granular permissions per category. Native + Hermes fallback for any model.
Dedicated coding mode. Reads your codebase, writes code, runs commands. File tree browser, native folder picker, working directory. Up to 20 iterations per task.
20+ provider presets. Local: Ollama, LM Studio, vLLM, KoboldCpp, llama.cpp, LocalAI, Jan, and more. Cloud: OpenAI, Anthropic, OpenRouter, Groq, Together, DeepSeek, Mistral. Switch per conversation.
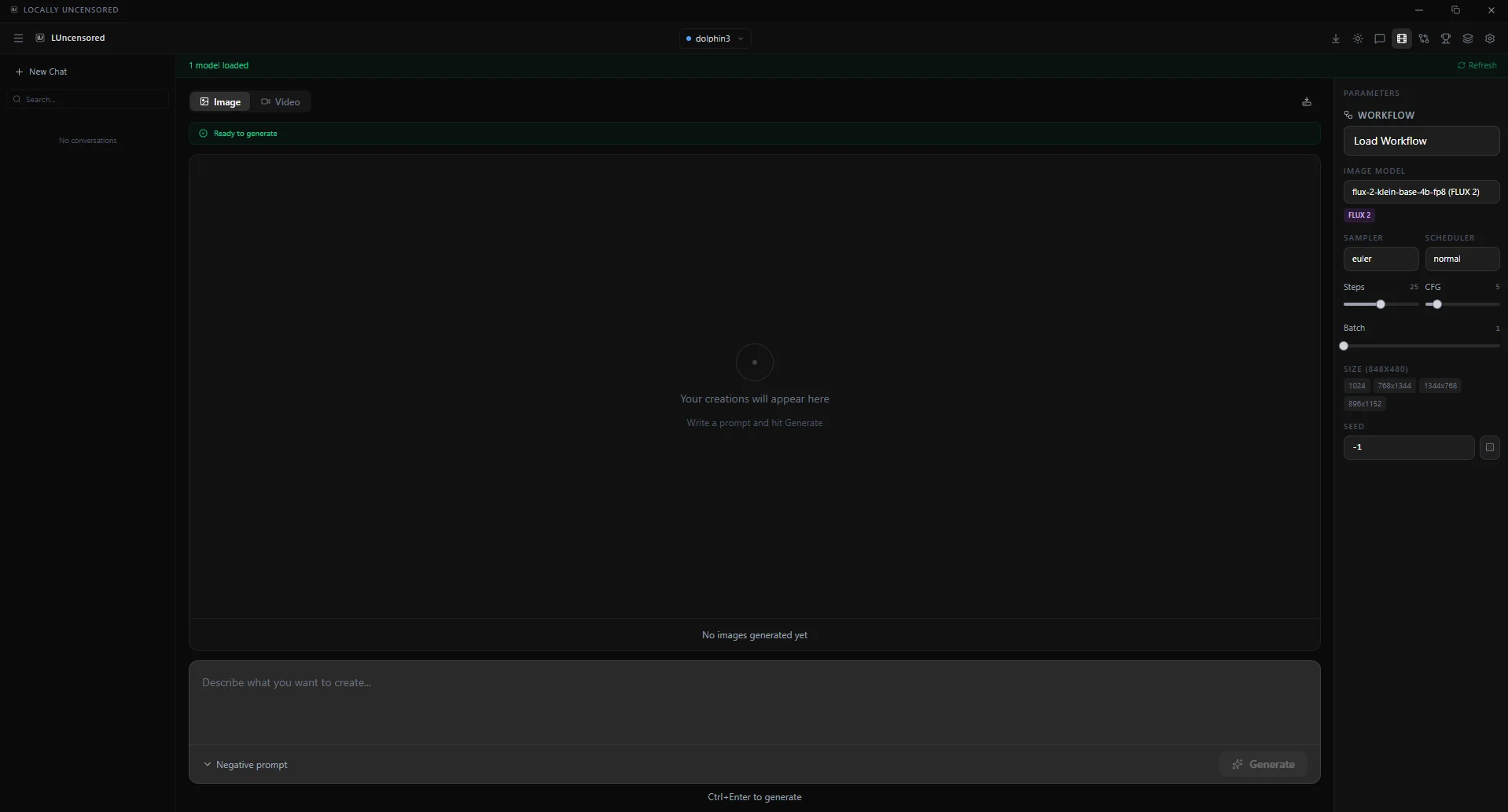
FLUX 2 Klein, FLUX.1, Z-Image Turbo, Juggernaut XL via ComfyUI. Text-to-Image and Image-to-Image. No content filter. One-click setup.
Wan 2.1, HunyuanVideo 1.5, LTX 2.3, AnimateDiff, FramePack F1 (I2V). Text-to-video and image-to-video on your GPU. No watermarks.
Drag & drop images, Ctrl+V paste screenshots, clip button. Vision models describe what they see. Up to 5 images per message.
7 tool categories (web, filesystem, terminal, system, desktop, image, workflow). Block, confirm, or auto-approve per category and per conversation.
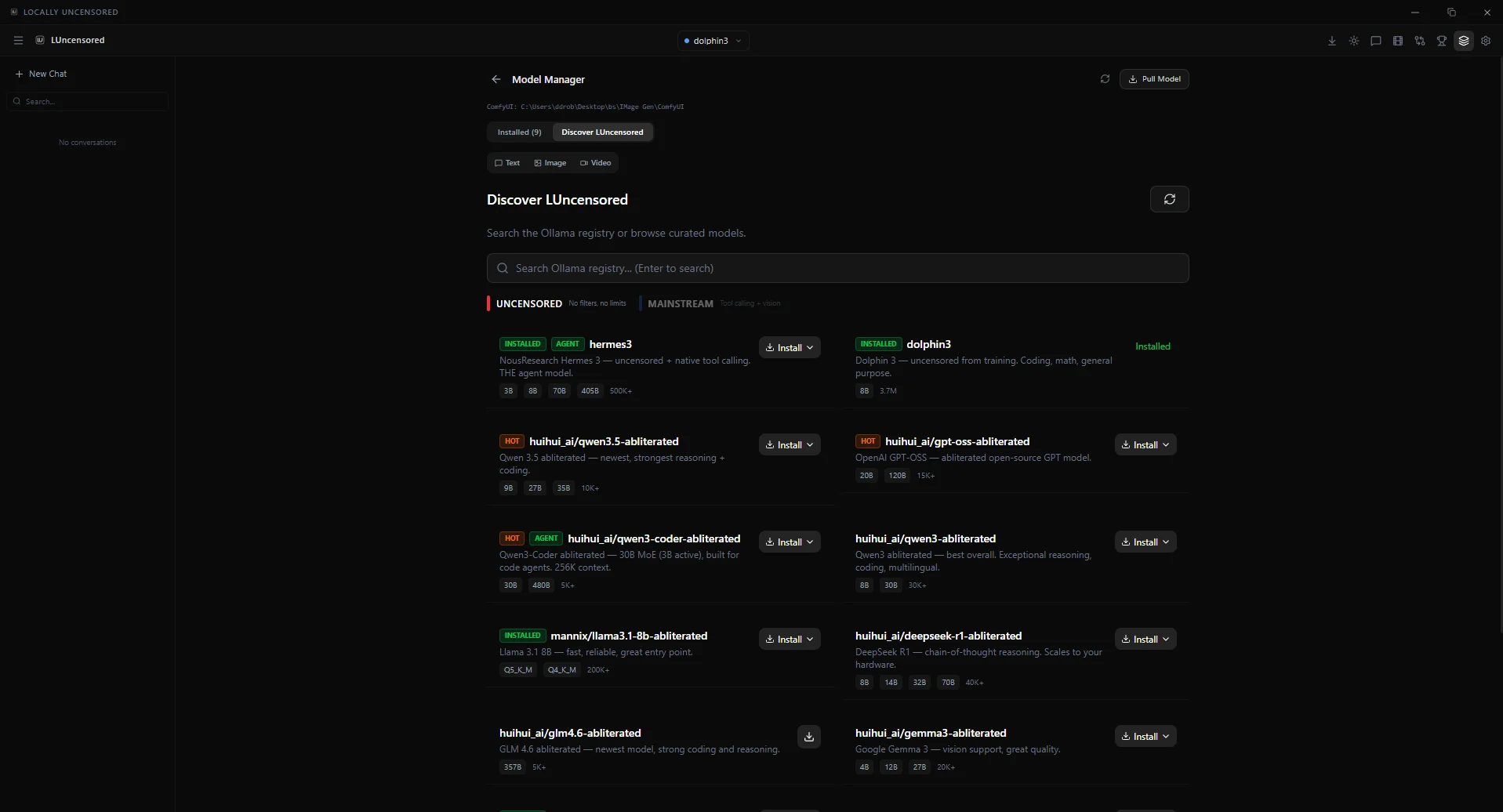
Browse, install, switch models. Auto-detects text, image, video. Load/unload from VRAM. Hardware-aware recommendations.
Toggle thinking for any provider. Native support where available, system prompt fallback for others. See the AI's reasoning in collapsible blocks before the answer.
First-launch wizard scans 12 local backends automatically. Ollama, LM Studio, vLLM, KoboldCpp, Jan, and more. Nothing installed? One-click install links for every backend. Zero config.
Dedicated coding mode. Reads your codebase, writes files, runs shell commands. File tree with native folder picker. Up to 20 iterations per task.
Dynamic tool registry: web_search, file_read, file_write, shell_execute, code_execute, system_info, screenshot, and more. Native + Hermes fallback.
7 categories: web, filesystem, terminal, system, desktop, image, workflow. Per-conversation overrides. Block, confirm, or auto-approve.
Attach images via clip button, drag & drop, or Ctrl+V paste. Vision models analyze images. Works across all providers.
Provider-agnostic. Native support where available, system prompt fallback for others. Collapsible thinking blocks in chat.
| Feature | Locally Uncensored | Open WebUI | LM Studio | SillyTavern |
|---|---|---|---|---|
| AI Chat | Yes | Yes | Yes | Yes |
| Plug & Play Setup | 12 Backends | No | Built-in | No |
| Multi-Provider | 20+ Presets | Yes | Yes | No |
| Coding Agent | Codex | No | No | No |
| Agent Tools (MCP) | 13 Tools | No | No | No |
| Image Generation | Yes | No | No | No |
| Image-to-Image | Yes | No | No | No |
| Video Generation | Yes | No | No | No |
| Image-to-Video | Yes | No | No | No |
| File Upload + Vision | Yes | Yes | Yes | No |
| Thinking Mode | Yes | No | No | No |
| Granular Permissions | 7 Categories | No | No | No |
| A/B Model Compare | Yes | No | No | No |
| Local Benchmark | Yes | No | No | No |
| Uncensored by Default | Yes | No | No | Partial |
| Open Source | AGPL-3.0 | MIT | No | AGPL |
| No Docker | Yes | Docker | Yes | Yes |
Download the .exe and install. That's it. No Docker, no terminal, no config files.
On first launch, the app scans for all 12 local backends automatically — Ollama, LM Studio, vLLM, KoboldCpp, Jan, and more. Found something? Connected. Nothing running? The wizard shows every backend with one-click install links.
Pick a model, start chatting. Switch to Codex for coding. Open Create for images and video. Add more providers anytime in Settings.
Google flagship. Native tools + vision. Apache 2.0. E4B runs on 4 GB, 27B on 16 GB. Recommended in onboarding.
Strongest reasoning + coding. 256K context. Abliterated variants available. 8-22 GB VRAM.
Next-gen + classic FLUX. 8-10 GB VRAM. Text-to-Image and Image-to-Image.
Explicitly uncensored. 8-15 seconds per image. No safety filters. T2I + I2I. 10-16 GB VRAM.
Text-to-video. Wan 1.3B (8 GB) for speed, 14B (12+ GB) for quality. HunyuanVideo for consistency.
Image-to-video on just 6 GB VRAM. Upload an image, get video. Revolutionary next-frame prediction.
A free, open-source desktop app for running AI locally. Combines uncensored chat, a coding agent (Codex) with 13 tools, image generation (ComfyUI), and video creation in one interface. 20+ provider presets: Ollama, LM Studio, vLLM, KoboldCpp, llama.cpp, LocalAI, Jan, OpenAI, Anthropic, OpenRouter, Groq, and more. AGPL-3.0 licensed.
Yes. After setup and model download, no internet needed. No accounts, no telemetry, no usage limits. Cloud providers are optional — the core runs 100% locally.
Those tools handle text chat. Locally Uncensored adds a coding agent with 13 MCP tools, image generation, video creation, A/B model comparison, local benchmarking, granular permissions, file upload with vision, and thinking mode. All in one app.
Text chat: 8 GB RAM. Images: NVIDIA GPU with 8+ GB VRAM. Video: 10-12 GB VRAM. The app recommends models based on your hardware. Windows 10/11.
Abliterated models with artificial restrictions removed. The AI responds honestly without refusing or adding disclaimers. Combined with local execution, your conversations are completely private.
All sizes from E4B to 27B. Native tools, vision, uncensored variants.
Upload a photo, adjust denoise, transform. FLUX, Z-Image, SDXL.
Complete comparison of GPT4All, Open WebUI, LM Studio, Jan, and more.
Setup guide. Models, hardware, and why local beats cloud.
Both open source. Only one does chat + code + images + video.
Open source all-in-one vs polished closed-source chat client.
Free, open source, and yours to keep.